참고:
- 책 <카프카,데이터 플랫폼의 최강자>
- 컨플루언트 블로그
Kafka란?
카프카는 대용량, 대규모 메시지 데이터를 빠르게 처리하도록 개발된 메시징 플랫폼입니다. 링크드인(LinkedIn)에서 처음 출발한 기술로 링크드인이 급속도로 성장하면서 발생하는 내부 이슈들을 해결하기 위해 탄생했습니다.
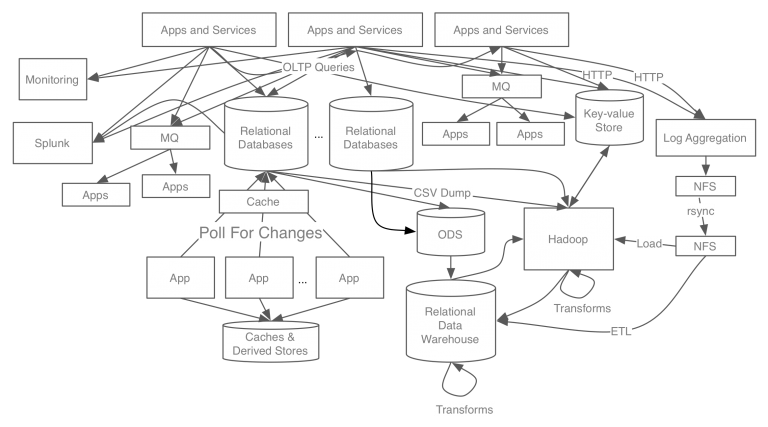
복잡도가 늘고 파이프라인이 파편화되면서 개발에 걸리는 시간이 늘어나고 파이프라인별로 데이터 포맷과 처리하는 방법들이 달라지면서 데이터를 신뢰할 수 없는 상황에 이르렀습니다. 카프카는 이러한 문제를 해결하기 위해 아래의 4가지 목표를 가지고 개발되었습니다.
- 프로듀서와 컨슈머의 분리
- 메시징 시스템과 같이 영구 메시지 데이터를 여러 컨슈머에 허용
- 높은 처리량을 위한 메시지 최적화
- 데이터가 증가함에 따라 스케일아웃이 가능한 시스템
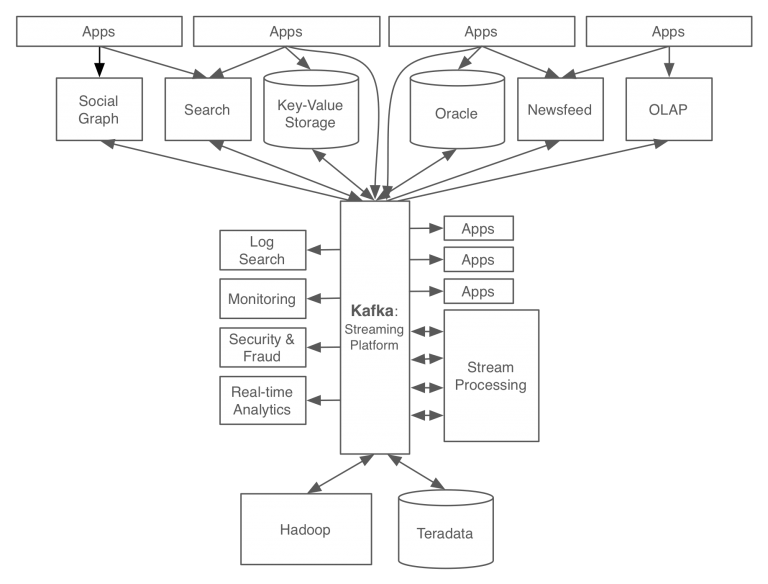
링크드인은 카프카를 적용하여 사내에서 발생하는 모든 이벤트와 데이터의 흐름을 중앙에서 관리할 수 있게 되었습니다. 또한, 새로운 데이터 스토어가 추가되어도 카프카가 제공하는 표준 포맷으로 연결되기 때문에 데이터를 주고받는데 문제가 없습니다.
링크드인은 카프카를 통해 하루에 약 1조개 이상의 메시지를 처리할 수 있으며 신뢰성 높은 데이터 분석과 실시간 분석이 가능해졌습니다.
Kafka의 동작방식
펍/섭 모델
중앙에 메시징 시스템 서버를 두고 메시지를 보내고 받는 형태의 통신
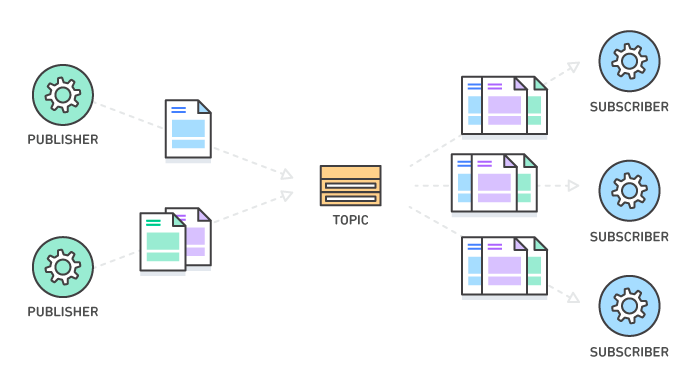
메시지라고 불리는 데이터 단위를 보내는 Producer(혹은 publisher)에서 카프카에 토픽이라는 각각의 메시지 저장소에 데이터를 저장하면 Consumer(혹은 subscriber)가 원하는 토픽에서 데이터를 가져갑니다.
기존의 메시징 모델은 각각의 개체가 메시징 시스템을 중심으로 연결되기 때문에 확장성이 용이하지만 메시지 전달 속도가 빠르지 않습니다. 카프카는 이와 같은 단점을 극복하기 위해 신뢰성 관리를 프로듀서와 컨슈머 쪽으로 넘기는 등 메시징 시스템 내의 작업량을 줄여 고성능 메시징 시스템을 만들어 냈습니다.
Kafka의 특징
✨프로듀서와 컨슈머의 분리
데이터를 보내는 역할과 데이터를 받는 역할을 분리하여 데이터 수집, 처리 시간을 단축할 수 있습니다.
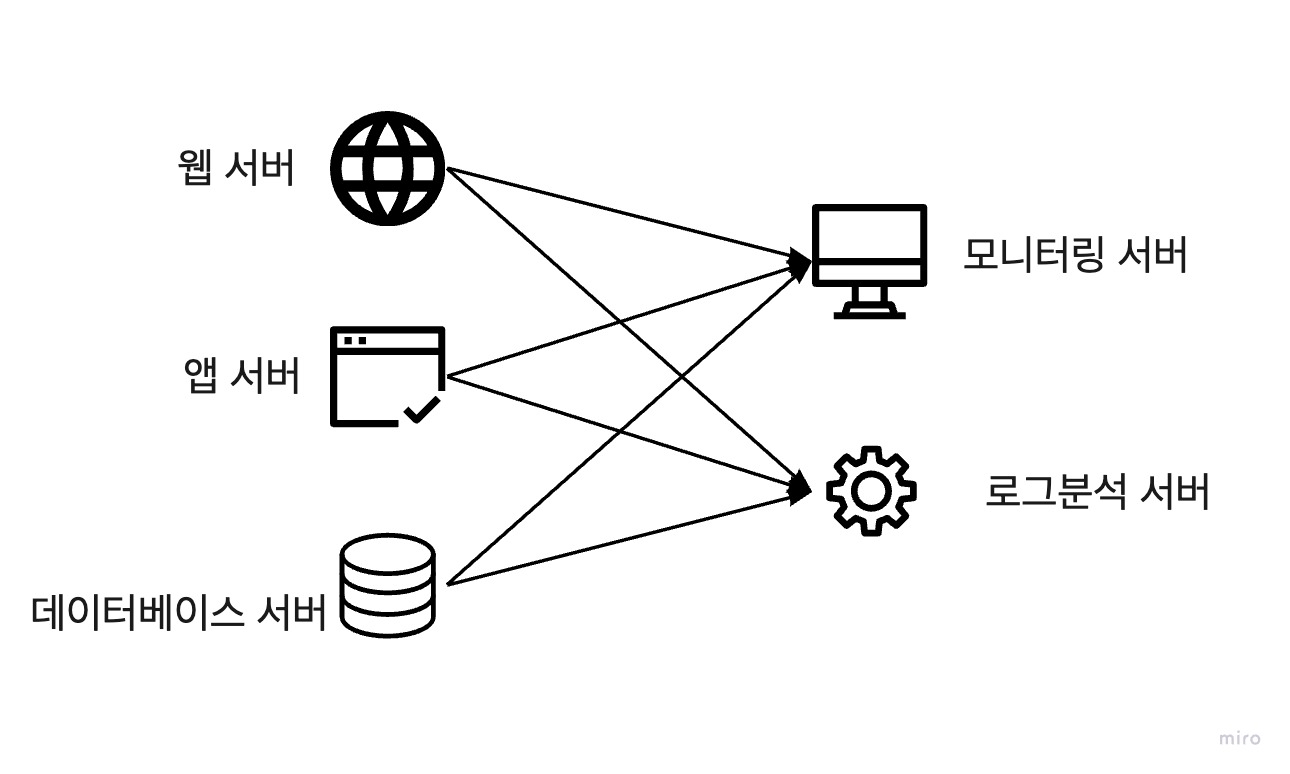
위의 그림과 같이 카프카를 사용하지 않은 시스템 구성에서는 서버 1대가 추가된다면 연동해야 할 시스템이 많아 추가적인 작업이 늘어납니다. 만약, 모니터링 서버에 문제가 생긴다면 모니터링 서버에 연결된 모든 서비스 서버들에서 이슈가 발생할 수 있습니다.
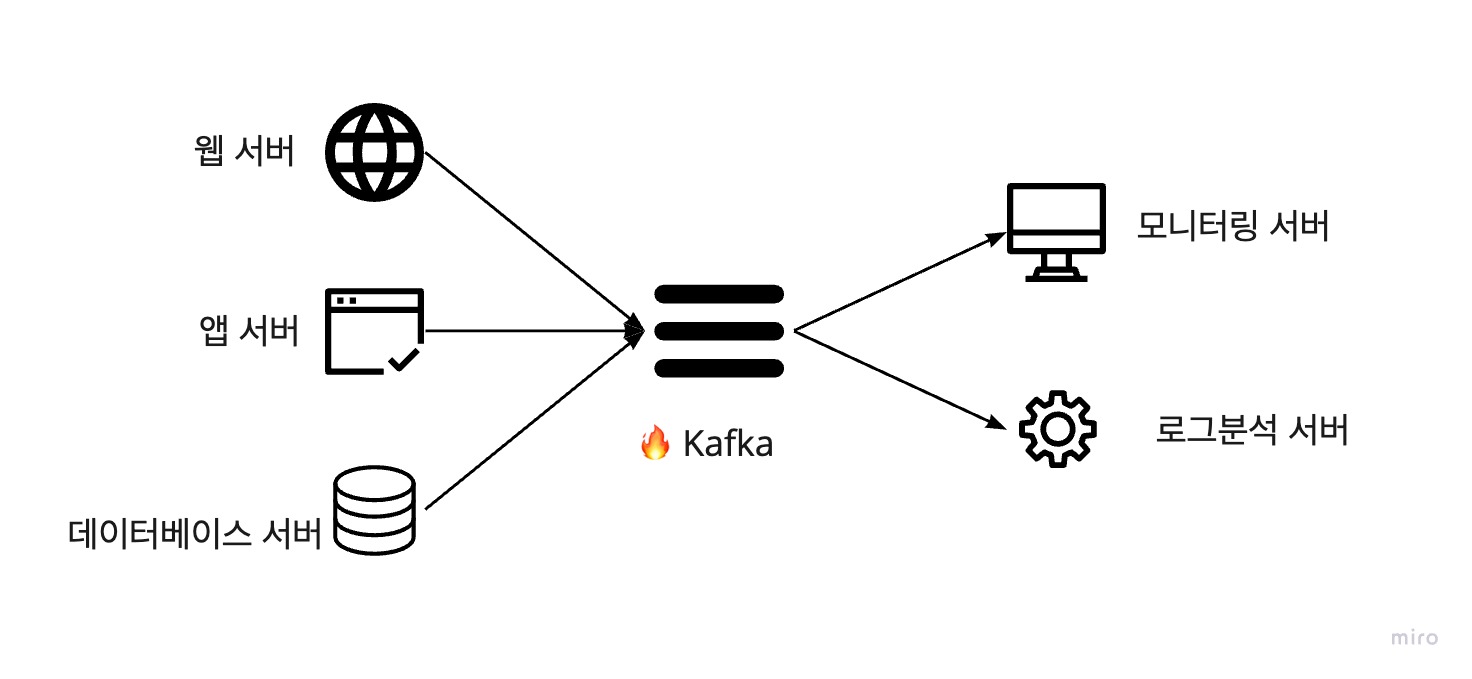
카프카를 사용한다면 구조가 매우 단순해지고 각 서비스 서버들은 다른 서비스 서버들의 상태와 상관없이 카프카로 메시지를 보내거나 카프카에 저장된 메시지를 가져오기만 하면 됩니다.
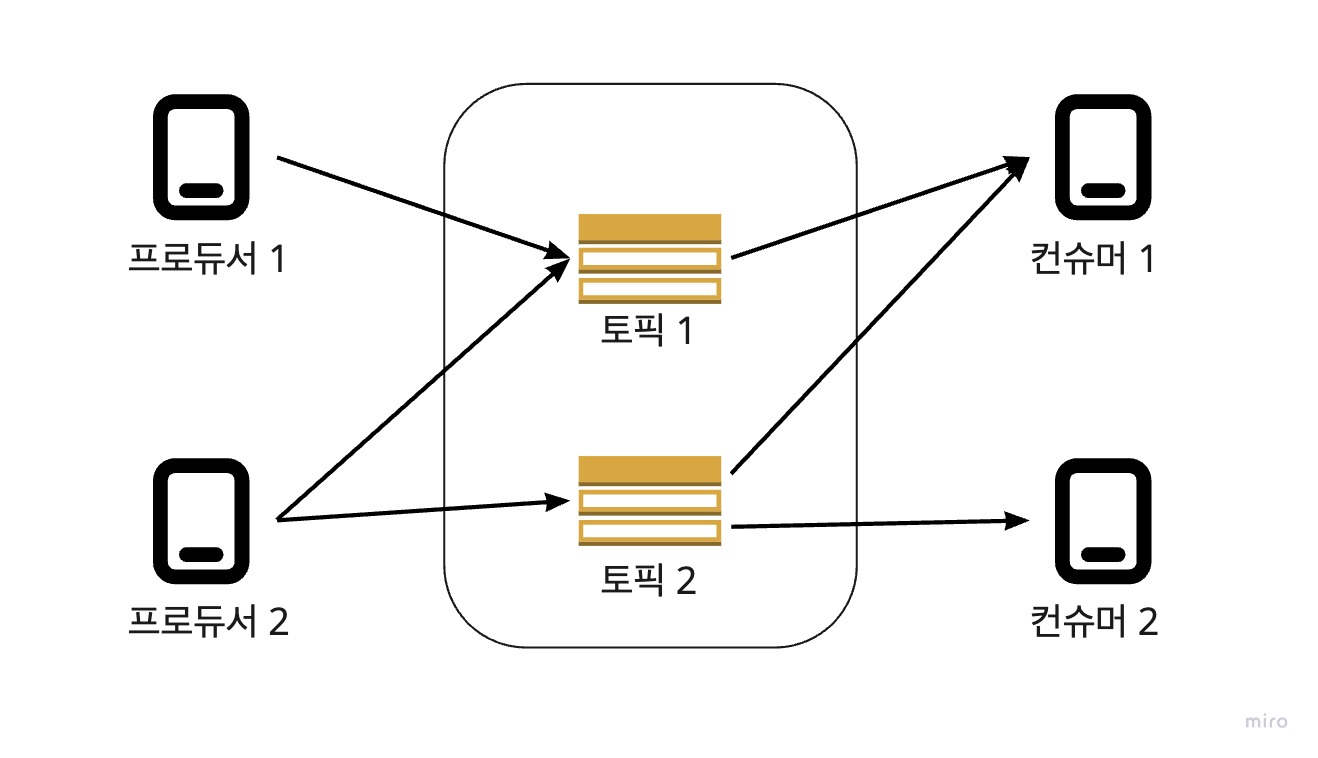
✨멀티 프로듀서, 멀티 컨슈머
하나의 토픽에 여러 프로듀서와 컨슈머들이 접근 가능합니다. 이러한 멀티 기능은 데이터 분석 및 처리 프로세스에서 하나의 데이터를 다양한 용도로 사용할 수 있게 합니다.
✨디스크에 메시지 저장
카프카는 디스크에 메시지를 저장하고 유지합니다. 일반적인 메시징 시스템들은 컨슈머가 메시지를 읽어가면 큐에서 메시지를 삭제합니다. 반면, 카프카는 컨슈머가 메시지를 읽어가도 정해진 보관 기간동안 디스크에 메시지를 저장합니다. 이를 통해 메시지 손실없이 작업이 가능해집니다.
✨확장성
클러스터를 확장하는 작업이 간단하고 부담없도록 설계되어 수십 대의 브로커로 확장이 가능합니다
(브로커 : 카프카 애플리케이션이 설치되어 있는 서버 또는 노드)
✨높은 성능
고성능을 유지하기 위해 내부적으로 분산 처리, 배치 처리, 페이지 캐시 등 다양한 기법을 사용합니다.
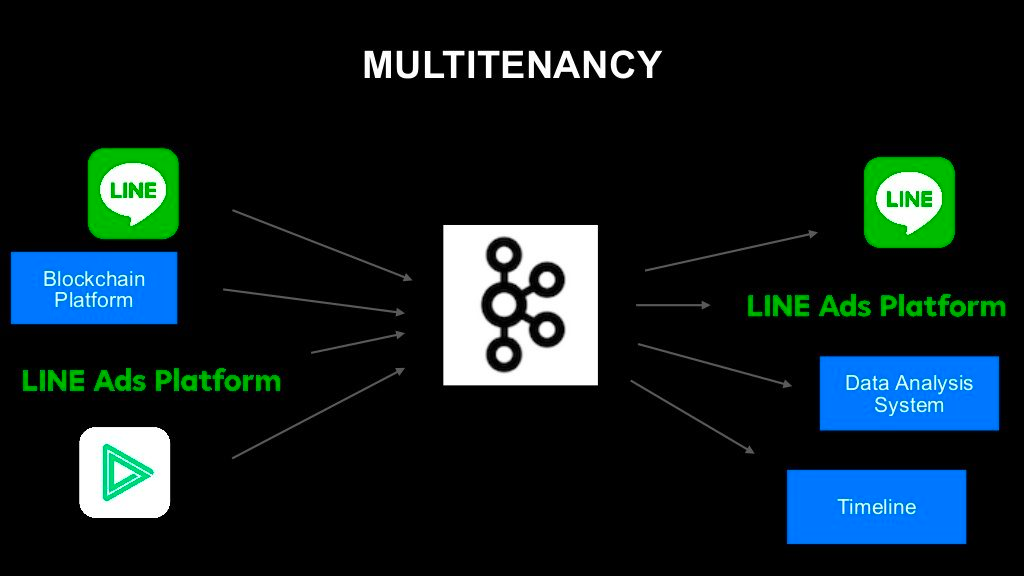
LINE에서 Kafka를 사용하는 방법
- 분산 큐잉 시스템 어떤 서비스의 웹 애플리케이션 서버에서 처리하는데 자원을 많이 사용해야 하는 업무가 발생했을 때, 이를 내부에서 처리하지 않고 다른 프로세스에서 작동 중인 백그라운드의 태스크 프로세서에 요청하기 위한 큐로 사용
- 데이터 허브
어떤 서비스에 데이터 업데이트가 발생했을 때, 해당 데이터를 사용하는 다른 여러 서비스에 전파하기 위한 허브로 사용
- 예시 유저 A가 유저 B를 친구로 추가 → 로직 수행, 업데이트 내용을 Kafka의 topic에 이벤트로 입력 → 통계 시스템이나 타임라인 등의 다른 서비스에서 사용
AWS Kinesis
참고 : 바로가기
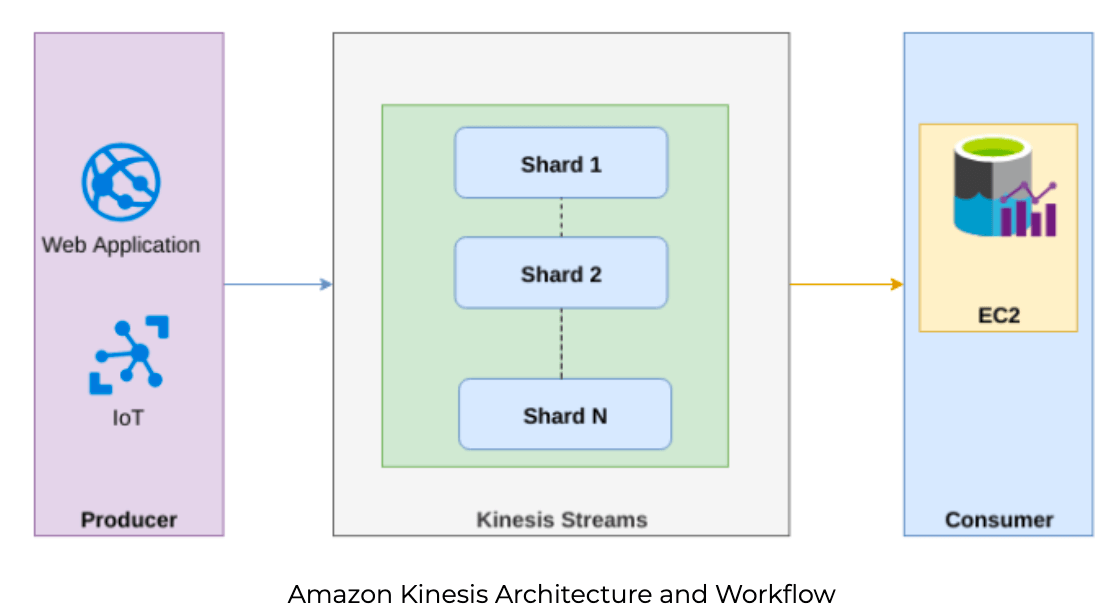
Kinesis는 AWS에서 제공하는 제품의 하나로 AWS가 운영, 관리를 도와주기 때문에 별도의 학습없이도 사용이 용이합니다. 반면, 오픈소스인 Kafka는 사용경험이 없다면 환경설정, 클러스터 운영, 오토스케일링, 로드밸런싱 등 학습이 필요해 실제 사용까지 기간이 소요됩니다.